
En este artículo se explica cómo se ejecuta Spark en un cluster, para facilitar la comprensión de los componentes involucrados. Las aplicaciones Spark se ejecutan como conjuntos independientes de procesos en un clúster, coordinados por el objeto SparkContext de tu programa principal (llamado programa controlador o driver).

Hay varias cosas útiles a tener en cuenta en esta arquitectura:
· Cada aplicación tiene sus propios procesos ejecutores, que permanecen activos durante toda la aplicación y ejecutan tareas en varios subprocesos. Esto tiene la ventaja de aislar las aplicaciones entre sí, tanto en el lado de la planificación (cada driver planifica sus propias tareas) como en el lado del ejecutor (las tareas de diferentes aplicaciones se ejecutan en diferentes JVM). Sin embargo, esto también significa que los datos no se pueden compartir entre diferentes aplicaciones Spark (instancias de SparkContext) sin escribirlos en un sistema de almacenamiento externo.
· Spark es independiente del administrador del clúster subyacente. Siempre que pueda adquirir procesos ejecutores, y estos se comuniquen entre sí, es relativamente fácil ejecutarlo incluso en un administrador de clúster que también soporte otras aplicaciones (por ejemplo, Mesos / YARN).
· El programa driver debe escuchar y aceptar conexiones entrantes desde sus ejecutores durante toda su vida (por ejemplo, consulta spark.driver.port en la sección de configuración de red). Como tal, el programa driver debe ser direccionable en la red desde los nodos worker.
· Puesto que el driver planifica las tareas en el clúster, debe ejecutarse cerca de los nodos worker, preferiblemente en la misma red de área local. Si deseas enviar solicitudes al clúster de forma remota, es mejor abrir una RPC al driver y hacer que envíe operaciones desde cerca que ejecutar un driver lejos de los nodos trabajadores.
Actualmente, el sistema soporta varios administradores de clústeres:
· Independiente: un administrador de clúster simple incluido con Spark que facilita la configuración de un clúster.
· Apache Mesos: un administrador de clúster general que también puede ejecutar Hadoop MapReduce y aplicaciones de servicio.
· Hadoop YARN: el administrador de recursos en Hadoop 2.
· Kubernetes: un sistema de código abierto para automatizar el despliegue, escalado y la administración de aplicaciones en contenedores.
Las aplicaciones se pueden enviar a un cluster de cualquier tipo mediante el script spark-submit.
Si tu código depende de otros proyectos, deberás empaquetarlos junto con tu aplicación para distribuir el código a un clúster Spark. Para hacer esto, crea un jar de ensamblaje (o "uber" jar) que contenga tu código y sus dependencias. Tanto sbt como Maven tienen plugins de ensamblaje. Al crear jars de ensamblaje, lista Spark y Hadoop como dependencias proporcionadas (provided); no es necesario incluirlas, ya que las proporciona el administrador del clúster en tiempo de ejecución. Una vez que tengas un jar ensamblado, puedes llamar al script bin/spark-submit como se muestra aquí mientras pasas tu jar.
Para Python, puedes usar el argumento --py-files de spark-submit para añadir archivos .py, .zip o .egg que se distribuirán con tu aplicación. Si dependes de varios archivos de Python, te recomiendo empaquetarlos en un .zip o .egg.
Una vez empaquetada una aplicación de usuario, se puede lanzar mediante el script bin/spark-submit. Este script se encarga de configurar el classpath con Spark y sus dependencias, y puede soportar diferentes administradores de clústeres y modos de despliegue soportados por Spark:

Algunas de las opciones más utilizadas son:
· --class: el punto de entrada de tu aplicación (por ejemplo, org.apache.spark.examples.SparkPi)
· --master: la URL maestra del clúster (por ejemplo, spark://23.195.26.187:7077)
· --deploy-mode: ya sea para desplegar tu driver en los nodos worker (clúster) o localmente como un cliente externo (client) (predeterminado: client) †
· --conf: propiedad de configuración de Spark arbitraria en formato clave=valor. Para valores que contienen espacios, coloca “clave=valor” entre comillas (como se muestra). Se deben pasar múltiples configuraciones como argumentos separados. (por ejemplo, --conf <clave>=<valor> --conf <clave2>=<valor2>)
· application-jar: ruta a un jar empaquetado que incluye tu aplicación y todas las dependencias. La URL debe ser visible globalmente dentro del clúster, por ejemplo, una ruta hdfs:// o una ruta file:// que esté presente en todos los nodos.
· application-arguments: argumentos pasados al método main de la clase principal, si los hay.
† Una estrategia de despliegue común es enviar tu aplicación desde una gateway que se ubica físicamente junto con las máquinas worker (p.e., un nodo maestro en un clúster EC2 independiente). En esta configuración, el modo cliente es apropiado. En modo cliente, el driver se lanza directamente dentro del proceso spark-submit que actúa como cliente del clúster. La entrada y salida de la aplicación se adjunta a la consola, por lo que este modo es especialmente adecuado para aplicaciones que implican al REPL (por ejemplo, el Spark shell).
Alternativamente, si tu aplicación se envía desde una máquina alejada de las máquinas worker (por ejemplo, localmente en tu portátil), es común usar el modo cluster para minimizar la latencia de la red entre los drivers y los ejecutores. Actualmente, el modo independiente no soporta el modo clúster para aplicaciones Python.
Para aplicaciones Python, simplemente pasa un archivo .py en el lugar de <application-jar> y añade los archivos .zip, .egg o .py de Python a la ruta de búsqueda con --py-files.
Hay algunas opciones disponibles que son específicas del administrador de clúster que se está utilizando. Por ejemplo, con un clúster independiente de Spark con modo de despliegue en cluster, también puedes especificar --supervise para asegurarte de que el driver se reinicie automáticamente si falla con un código de salida distinto de cero. Para listar todas las opciones disponibles de spark-submit, ejecútalo con --help. A continuación, se muestran algunos ejemplos de opciones comunes:


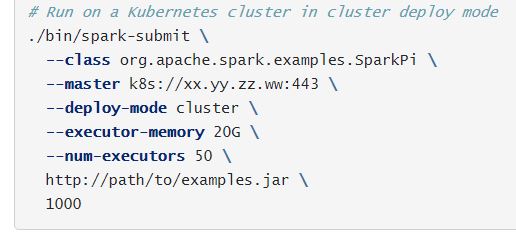
La URL maestra que se pasa a Spark puede tener uno de los siguientes formatos:
URL Maestra | Significado |
local | Ejecutar Spark localmente con un hilo de trabajo (es decir, sin paralelismo). |
local[K] | Ejecutar Spark localmente con K hilos de trabajo (idealmente, establece esto a la cantidad de núcleos de tu máquina). |
local[K,F] | Ejecutar Spark localmente con K hilos de trabajo K y F maxFailures (consulta spark.task.maxFailures para obtener una explicación de esta variable) |
Local[*] | Ejecutar Spark localmente con tantos hilos de trabajo como núcleos lógicos haya en tu máquina. |
Local[*,F] | Ejecutar Spark localmente con tantos hilos de trabajo como núcleos lógicos haya en tu máquina y F maxFailures. |
spark://HOST:PORT | Conectarse al maestro del clúster independiente de Spark proporcionado. El puerto debe ser el que su maestro esté configurado para usar, que es 7077 por defecto. |
spark://HOST1:PORT1,HOST2:PORT2 | Conectarse al clúster independiente de Spark con maestros en espera con Zookeeper. La lista debe tener todos los hosts maestros del clúster de alta disponibilidad configurados con Zookeeper. El puerto debe ser el que cada maestro esté configurado para usar, que es 7077 por defecto. |
mesos://HOST:PORT | Conectarse al clúster de Mesos dado. El puerto debe ser el que esté configurado para usar, que es 5050 por defecto. O, para un clúster Mesos que usa ZooKeeper, usa mesos://zk://.... Para enviar con el --deploy-mode cluster, el HOST: PORT debe configurarse para conectarse al MesosClusterDispatcher. |
yarn | Conectarse a un clúster YARN en modo client o cluster según el valor de --deploy-mode. La ubicación del clúster se encontrará en función de la variable HADOOP_CONF_DIR o YARN_CONF_DIR. |
k8s://HOST:PORT | Conectarse a un clúster Kubernetes en modo cluster. El modo cliente no está soportado actualmente y estará soportadp en versiones futuras. HOST y PORT se refieren al servidor API de Kubernetes. Se conecta mediante TLS de forma predeterminada. Para forzarlo a usar una conexión no segura, puedes usar k8s://http://HOST: PORT. |
El script spark-submit puede cargar valores de configuración de Spark predeterminados desde un archivo de propiedades y pasarlos a tu aplicación. De forma predeterminada, leerá las opciones de conf/spark-defaults.conf en el directorio Spark. Para obtener más detalles, consulta la sección sobre la carga de configuraciones predeterminadas.
La carga de las configuraciones predeterminadas de Spark de esta manera puede evitar la necesidad de ciertos indicadores en spark-submit. Por ejemplo, si se establece la propiedad spark.master, puedes omitir con seguridad la marca --master de spark-submit. En general, los valores de configuración establecidos explícitamente en una SparkConf tienen la mayor prioridad, luego los indicadores que se pasan a spark-submit y luego los valores en el archivo de valores predeterminados.
Si alguna vez no tienes claro de dónde provienen las opciones de configuración, puedes imprimir información de depuración detallada ejecutando spark-submit con la opción --verbose.
Al usar spark-submit, el jar de la aplicación junto con los jar incluidos con la opción --jars se transferirán automáticamente al clúster. Las URL proporcionadas después de --jars deben estar separadas por comas. Esa lista se incluye en los classpaths del driver y del ejecutor. La expansión de directorios no funciona con --jars.
Spark utiliza el siguiente esquema de URL para permitir diferentes estrategias para difundir archivos jar:
· file: - Las URIs de rutas absolutas y file:/ son servidas por el servidor de archivos HTTP del driver, y cada ejecutor extrae el archivo del servidor HTTP del driver.
· hdfs:, http:, https:, ftp: - estos extraen archivos y JARs del URI como se espera.
· local: - un URI que comienza con local:/ se espera que exista como un archivo local en cada nodo worker. Esto significa que no se incurrirá en E/S de red y funciona bien para archivos/JARs grandes que se envían a cada worker o se comparten a través de NFS, GlusterFS, etc.
Ten en cuenta que los archivos JAR y los archivos se copian en el directorio de trabajo para cada SparkContext en los nodos ejecutores. Esto puede consumir una cantidad significativa de espacio con el tiempo y deberá limpiarse. Con YARN, la limpieza se gestiona automáticamente y con Spark standalone, la limpieza automática se puede configurar con la propiedad spark.worker.cleanup.appDataTtl.
Los usuarios también pueden incluir cualquier otra dependencia proporcionando una lista delimitada por comas de coordenadas Maven con --packages. Todas las dependencias transitivas se manejarán al usar este comando. Se pueden añadir repositorios adicionales (o resolutores en SBT) delimitados por comas con el indicador --repositories. (Ten en cuenta que las credenciales para repositorios protegidos con contraseña se pueden proporcionar en algunos casos en el URI del repositorio, como en https://usuario:contraseña@host/.... Ten cuidado al proporcionar credenciales de esta manera). Estos comandos se pueden usar con pyspark, spark-shell y spark-submit para incluir paquetes Spark.
Para Python, la opción equivalente --py-files se puede usar para distribuir librerías .egg, .zip y .py a los ejecutores.
Video Ejemplo 1:
Video Ejemplo 2: Creación de una aplicación Spark con Scala usando Maven en IntelliJ 2-2 (la música de fondo es un poco molesta, pero el ejemplo es útil).
Referencia(s):
https://mahendranp.medium.com/spark-scala-maven-intellij-spark-3-0-8cad6eb7f799
Mi primera aplicación Apache Spark en Scala con Maven usando IntelliJ:
https://www.diegocalvo.es/mi-primera-aplicacion-apache-spark-en-scala-con-maven-en-intelligent-idea/
En el siguiente artículo trataré sobre la monitorización de aplicaciones Spark.
Buen aprendizaje !!!
0 comentarios:
Publicar un comentario
Gracias por participar en esta página.