Armar tú propio paquete de software desde cero puede ser un lío y mucho trabajo si eres un principiante. La tarea de configurar todos los c...


Armar tú propio paquete de software desde cero puede ser un lío y mucho trabajo si eres un principiante. La tarea de configurar todos los c...
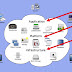
Hay muchos niveles de servicio que pueden ofrecer los proveedores de la nube. Cualquier debate sobre procesamiento en la nube implica temas...
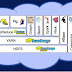
Al principio de este curso comentaba que la nube ha sido uno de los factores que han influido en la puesta en marcha de la era Big Data. Se...

El ecosistema Hadoop está creciendo a un ritmo rápido. Esto significa que está siendo posible hacer muchas cosas que antes eran difíciles o...

MapReduce es un modelo de programación para el ecosistema Hadoop . Se basa en YARN para planificar y ejecutar el procesamiento en paralelo ...

La mayor parte de la ejecución se realiza en un único nodo. Si la ejecución necesita más de un nodo o del procesamiento en paralelo, como s...

YARN es un gestor de recursos que se sitúa justo por encima de la capa de almacenamiento, HDFS . YARN interactúa con las aplicaciones para ...

El sistema de ficheros distribuidos de Hadoop ( HDFS ) sirve como capa base de almacenamiento para la mayoría de las herramientas del ecos...
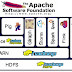
Todos hemos oído que los proyectos de Hadoop y relacionados con este ecosistema son ideales para los grandes volúmenes de datos. En esta se...

Hemos visto que ahora es posible el procesamiento escalable en Internet para conseguir la escalabilidad de datos en paralelo en las aplicac...